

2024 Uluslararası Matematik Olimpiyatı’nda (IMO) bir yarışmacı o kadar başarılı oldu ki Gümüş Ödül’e layık görüldü, tek bir şey dışında: bu bir yapay zeka sistemiydi. Bu, yarışma tarihinde yapay zekanın madalya düzeyinde bir performansa ulaştığı ilk seferdi. Dergide yayınlanan bir makalede DoğaAraştırmacılar bu olağanüstü başarının ardındaki teknolojiyi ayrıntılarıyla anlatıyor.
Yapay zeka, Google DeepMind tarafından geliştirilen ve karmaşık matematik problemlerini çözmeyi öğrenen karmaşık bir program olan AlphaProof’tur. IMO’daki başarı yeterince etkileyiciydi ancak AlphaProof’u gerçekten özel kılan şey, hataları bulma ve düzeltme yeteneğidir. Büyük dil modelleri (LLM’ler) matematik problemlerini çözebilse de çoğu zaman çözümlerinin doğruluğunu garanti edemezler. Akıl yürütmelerinde gizli kusurlar olabilir.
AlphaProof farklıdır çünkü cevapları her zaman %100 doğrudur. Bunun nedeni, her mantıksal adımı doğrulayan katı bir öğretmen gibi davranan, Yalın (başlangıçta Microsoft Research tarafından geliştirilen) adı verilen özel bir yazılım ortamı kullanmasıdır. Bu, bilgisayarın yanıtları kendisinin doğruladığı, dolayısıyla sonuçlarının güvenilir olduğu anlamına gelir.
Üç aşamalı eğitim süreci
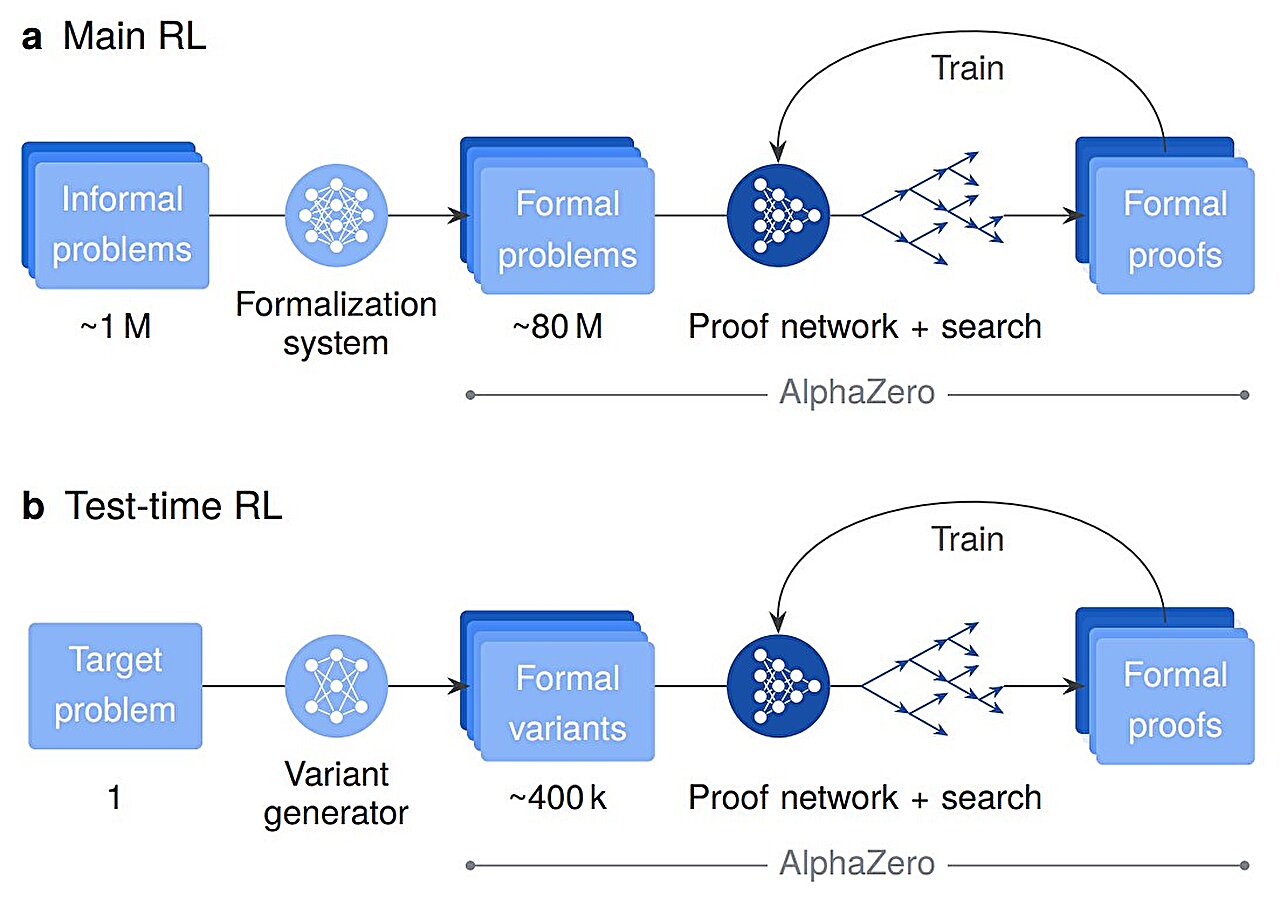
Bu güçlü sistemi elit düzeyde akıl yürütmeye yönelik eğitmek, üç farklı eğitim aşamasını içeriyordu. İlk olarak araştırmacılar, AlphaProof’a mantık, matematik dili ve programlama yapısı gibi kavramların geniş bir şekilde anlaşılmasını sağlamak için yaklaşık 300 milyar jetonluk genel kod ve matematiksel metni maruz bıraktılar. Daha sonra kendisine Yalın ortamda bulunan uzmanlar tarafından yazılan 300.000 matematik kanıtı verildi.
Son aşama, sistemin sorunları kendi başına çözmeyi öğrendiği aşamaydı. Çözülmesi gereken 80 milyon resmi matematik probleminden oluşan devasa bir ev ödevi verildi. Deneme yanılmaya dayalı Güçlendirme Öğrenimini (RL) kullanan AlphaProof, her başarılı kanıt için ödüllendirildi. Sistem, matematik problemlerini bu kadar büyük ölçekte ele alarak, insan örneklerini kopyalamanın ötesine geçen yeni ve karmaşık akıl yürütme stratejilerini kendine öğretti.
En zorlu problemler için AlphaProof, araştırmacıların geliştirdiği Test-Time RL (TTRL) adı verilen ve bir çözüm bulana kadar hedef problemin milyonlarca basitleştirilmiş versiyonunu oluşturup çözen bir teknik kullandı.
Araştırmacılar makalelerinde “Çalışmamız, temel deneyimlerden geniş ölçekte öğrenmenin, karmaşık matematiksel akıl yürütme stratejilerine sahip aracılar ürettiğini ve karmaşık matematiksel problem çözmede güvenilir bir yapay zeka aracının önünü açtığını gösteriyor” diye yazdı.
AlphaProof, görünüşte zorlu matematik problemlerini çözmenin yanı sıra, matematikçiler tarafından çalışmalarını düzeltmek ve yeni teoriler geliştirmelerine yardımcı olmak için de kullanılabilir.
Sizin için yazarımız Paul Arnold tarafından yazılan, Gaby Clark tarafından düzenlenen ve Robert Egan tarafından gerçekleri kontrol edilen ve gözden geçirilen bu makale, insanların dikkatli çalışmasının sonucudur. Bağımsız bilim gazeteciliğini canlı tutmak için sizin gibi okuyuculara güveniyoruz. Bu raporlama sizin için önemliyse lütfen bağış yapmayı düşünün (özellikle aylık). Bir alacaksın reklamsız bir teşekkür olarak hesaplayın.
